import pandas as pd
import numpy as np
import statistics as sts
import matplotlib.pyplot as plt
import seaborn as snsO impacto global das drogas de qualidade

Num contexto social, as drogas podem ter efeitos divergentes. Por um lado, o uso apropriado de medicamentos contribui para a integração de indivíduos na sociedade, permitindo que mantenham uma vida funcional. Por outro lado, o abuso de drogas pode resultar em problemas sociais, como aumento da criminalidade, desintegração familiar e marginalização. Isso muito se dá, além do aumento da produção e tráfico de drogas, pelo aumento da qualidade das drogas que chegam às mãos de quem as faz consumo.
Como dito, as drogas lícitas de alta qualidade contribuem para a nossa sociedade, porém o aumento da pureza das drogas ilícitas apresenta desafios significativos para a sociedade global. Em termos de saúde, a intensificação dos efeitos dessas drogas pode resultar em overdoses acidentais e complicações médicas sérias, contribuindo para uma carga adicional nos sistemas de saúde. Além disso, a ligação entre o aumento da pureza e o tráfico internacional frequentemente alimenta a violência e a criminalidade associadas ao mercado de drogas, com grupos criminosos disputando territórios e rotas de distribuição.
Com isso, o vício e a dependência também são agravados, uma vez que drogas mais puras tendem a levar a uma dependência mais rápida, gerando não apenas impactos na saúde individual, mas também em toda uma sociedade.
O meu objetivo com este estudo é mostrar o impacto que as drogas de qualidade (“alta pureza”) têm na sociedade em nível global, usando técnicas de análise de dados. Para isso, farei uso de dados oficiais disponibilizados pela UNODC (United Nations Office on Drugs and Crime).
Data First View
No site oficial da UNODC pode-se encontrar diversas bases de dados, sobre tráfico, venda, compra, qualidade, produção de drogas, entre outros. Para nosso objetivo, a base de dados de qualidade (pureza), já é o suficiente. Farei a importação das bibliotecas usadas para análise de dados e verei os dados pela primeira vez.
purities = pd.read_csv('purities.csv')
purities.head()| Source | Region | SubRegion | Country/Territory | DrugGroup | Drug | DrugState | LevelOfSale | Year | Typical purity | Minimum purity | Maximum purity | Purity | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ARQ | Africa | East Africa | Kenya | Cocaine-type | Cocaine | NaN | Wholesale | 2019 | 0,15 | 0,25 | 0,30 | % (percent) |
| 1 | ARQ | Africa | East Africa | Kenya | Cocaine-type | Cocaine | NaN | Street | 2019 | 0,10 | 0,05 | 0,15 | % (percent) |
| 2 | ARQ | Africa | East Africa | Kenya | Opioids | Heroin | NaN | Street | 2019 | 0,10 | 0,05 | 0,15 | % (percent) |
| 3 | ARQ | Africa | East Africa | Kenya | Opioids | Heroin | NaN | Wholesale | 2019 | 0,25 | 0,30 | 0,60 | % (percent) |
| 4 | ARQ | Africa | North Africa | Algeria | Cannabis-type drugs | Cannabis resin (hashish) | NaN | Street | 2018 | 0,13 | 0,05 | 0,20 | % (percent) |
purities.shape(1561, 13)Em uma primeira impressão de meus dados de pureza, vejo que tenho 1561 registros distribuídos em 13 features (colunas).
Um Data dictionary é sempre a melhor opção a se fazer (caso não o tenha) no inicio de uma análise de dados, com isso podemos entender melhor do que se tratam nossos dados. Veja abaixo:
- Source - Fonte, organização a qual os dados foram recolhidos.
- Region - Região, continente de onde são os dados.
- SubRegion - Subregião, norte, sul, etc.
- Country/Territory - País ou território.
- DrugGroup - Grupo a qual a droga pertence.
- Drug - Nome da droga em si.
- DrugState - Estado da droga (pó, tabletes ou liquido).
- LevelOfSale - Nivel de venda (atacado, varejo ou de rua).
- Year - Ano
- Typical purity - Pureza Típica.
- Minimum purity - Pureza Mínima
- Maximum purity - Pureza Máxima
- Purity - Unidades de medida da pureza.
purities.dtypesSource object
Region object
SubRegion object
Country/Territory object
DrugGroup object
Drug object
DrugState object
LevelOfSale object
Year int64
Typical purity object
Minimum purity object
Maximum purity object
Purity object
dtype: objectAcima vemos que a maioria dos meus dados estão em formato object (menos os dados de anos). Isso significa que terei que transformar os dados de pureza para Float mais a frente pois são minhas features target.
purities.isna().sum()Source 0
Region 0
SubRegion 0
Country/Territory 0
DrugGroup 0
Drug 4
DrugState 1421
LevelOfSale 0
Year 0
Typical purity 207
Minimum purity 184
Maximum purity 172
Purity 0
dtype: int64Observando a soma da quantidade de dados faltantes no dataset de Pureza vemos que em ‘DrugState’ quase não temos dados, então o ideal aqui talvez seja deletar a Feature. Temos alguns dados faltantes em pureza, esses serão substituídos pela mediana.
for col in purities.columns:
porcentagem = round(purities[col].isna().mean() * 100, 2)
print(f'{col}: {porcentagem}%')Source: 0.0%
Region: 0.0%
SubRegion: 0.0%
Country/Territory: 0.0%
DrugGroup: 0.0%
Drug: 0.26%
DrugState: 91.03%
LevelOfSale: 0.0%
Year: 0.0%
Typical purity: 13.26%
Minimum purity: 11.79%
Maximum purity: 11.02%
Purity: 0.0%Apenas a titulo de curiosidade, acima temos a porcentagem de dados faltantes por Feature.
Tratamento de dados
Na seção anterior eu mencionei que eu teria que fazer a transformação do tipo dos dados, farei essa transformação no inicio de meu projeto afim de me ajudar a fazer analises estatísticas e um tratamento adequado.
columns_to_convert = ['Typical purity', 'Minimum purity', 'Maximum purity']
purities[columns_to_convert] = purities[columns_to_convert].apply(lambda x: x.str.replace(',', '.').astype(float))
purities[['Typical purity', 'Minimum purity', 'Maximum purity']] = purities[columns_to_convert]Acima podemos ver como eu resolvi o problema. Primeiro eu teria que substituir a ‘,’ por ‘.’ para que eu pudesse fazer a transformação de dados categóricos para dados numéricos de tipo Float como podem ver abaixo.
purities.dtypesSource object
Region object
SubRegion object
Country/Territory object
DrugGroup object
Drug object
DrugState object
LevelOfSale object
Year int64
Typical purity float64
Minimum purity float64
Maximum purity float64
Purity object
dtype: objectFinalmente temos os dados nos formatos que preciso.
Lidando com Dados Ausentes
Relembrarei em quais Features temos dados ausentes:
purities.isna().sum()Source 0
Region 0
SubRegion 0
Country/Territory 0
DrugGroup 0
Drug 4
DrugState 1421
LevelOfSale 0
Year 0
Typical purity 207
Minimum purity 184
Maximum purity 172
Purity 0
dtype: int64for col in ["Typical purity", "Minimum purity", "Maximum purity"]:
purities[col].fillna(purities[col].median(), inplace=True)Primeiro eu substituo os dados faltantes da Pureza pela mediana de suas respectivas colunas.
purities = purities.dropna(subset=['Drug'])Excluo as linhas dos unicos 4 dados faltantes da Feature ‘Drug’.
del purities['DrugState']Deleto toda a Feature ‘DrugState’ pela quantidade de dados ausentes, por ser uma coluna categórica não teria como substituir por outro valor.
for col in purities.columns:
porcentagem = round(purities[col].isna().mean() * 100, 2)
print(f'{col}: {porcentagem}%')Source: 0.0%
Region: 0.0%
SubRegion: 0.0%
Country/Territory: 0.0%
DrugGroup: 0.0%
Drug: 0.0%
LevelOfSale: 0.0%
Year: 0.0%
Typical purity: 0.0%
Minimum purity: 0.0%
Maximum purity: 0.0%
Purity: 0.0%E finalmente temos nosso dataset de Pureza sem dados faltantes.
Verificando erros nos dados
Primeiro verei se não temos dados negativos ou valores discrepantes, os quais podem atrapalhar meu EDA.
Terei que antes de tudo multiplicar todas as minhas porcentagens por 100, para que assim a porcentagem fique em um formato agradável para a realização de minha EDA.
purities[['Typical purity', 'Minimum purity', 'Maximum purity']] = purities[['Typical purity', 'Minimum purity', 'Maximum purity']] * 100Abaixo farei uma descrição estatística de meus datasets:
purities.describe().T| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Year | 1557.0 | 2018.035967 | 1.448780 | 2016.0 | 2017.0 | 2018.0 | 2019.0 | 2020.0 |
| Typical purity | 1557.0 | 1569.157354 | 3677.239246 | 1.0 | 29.0 | 66.0 | 760.0 | 47720.0 |
| Minimum purity | 1557.0 | 607.101477 | 2218.524604 | 0.0 | 2.0 | 18.0 | 69.0 | 40110.0 |
| Maximum purity | 1557.0 | 2561.240206 | 5867.481023 | 0.0 | 64.0 | 85.0 | 1800.0 | 73390.0 |
fig, ax = plt.subplots(1, 3)
sns.distplot(purities["Typical purity"], ax=ax[0]).set_title('Pureza Tipica')
sns.distplot(purities["Minimum purity"], ax=ax[1]).set_title('Pureza Minima')
sns.distplot(purities["Maximum purity"], ax=ax[2]).set_title('Pureza Máxima')UserWarning:
`distplot` is a deprecated function and will be removed in seaborn v0.14.0.
Please adapt your code to use either `displot` (a figure-level function with
similar flexibility) or `histplot` (an axes-level function for histograms).
For a guide to updating your code to use the new functions, please see
https://gist.github.com/mwaskom/de44147ed2974457ad6372750bbe5751
sns.distplot(purities["Typical purity"], ax=ax[0]).set_title('Pureza Tipica')
<ipython-input-16-0eae6e665658>:3: UserWarning:
`distplot` is a deprecated function and will be removed in seaborn v0.14.0.
Please adapt your code to use either `displot` (a figure-level function with
similar flexibility) or `histplot` (an axes-level function for histograms).
For a guide to updating your code to use the new functions, please see
https://gist.github.com/mwaskom/de44147ed2974457ad6372750bbe5751
sns.distplot(purities["Minimum purity"], ax=ax[1]).set_title('Pureza Minima')
<ipython-input-16-0eae6e665658>:4: UserWarning:
`distplot` is a deprecated function and will be removed in seaborn v0.14.0.
Please adapt your code to use either `displot` (a figure-level function with
similar flexibility) or `histplot` (an axes-level function for histograms).
For a guide to updating your code to use the new functions, please see
https://gist.github.com/mwaskom/de44147ed2974457ad6372750bbe5751
sns.distplot(purities["Maximum purity"], ax=ax[2]).set_title('Pureza Máxima')Text(0.5, 1.0, 'Pureza Máxima')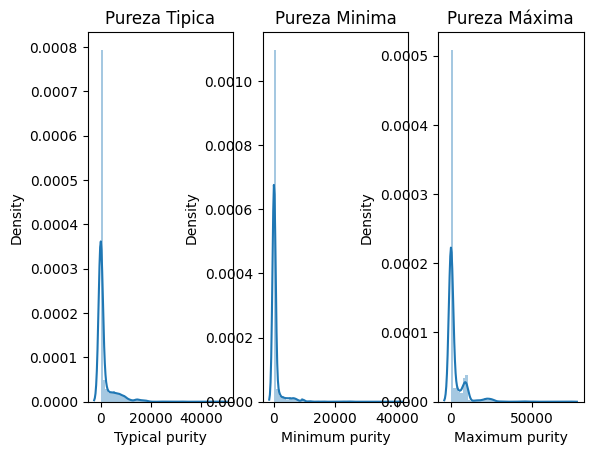
Tanto nos gráficos acima quanto nas descrições estatísticas vemos que temos dados discrepantes. Não temos dados negativos, é algo bom. Porém antes de resolver esse problema, irei resolver o problema descrito abaixo:
Temos um pequeno problema em nosso dataset de Pureza, a qualidade da droga é definida tanto em porcentagem quanto em mg/Tablets, logo terei que normalizar isso em apenas 1 medida, a mais frequente é a porcentagem, então irei excluir os dados que contem mg/Tablets.
purities['Purity'].unique()array(['% (percent)', 'Mg/Tablet', 'mg/tablet'], dtype=object)purities = purities.loc[~purities['Purity'].str.contains('Mg/Table|mg/tablet')]purities['Purity'].unique()array(['% (percent)'], dtype=object)Excluído os dados que não estão em porcentagem, agora sim teremos uma melhor noção se temos ou não outliers no nosso dataset de pureza. Resolvido esse pequeno empecilho, irei resolver o próximo, o de dados discrepantes:
purities.loc[(purities['Typical purity'] > 100) | (purities['Minimum purity'] > 100) | (purities['Maximum purity'] > 100)]| Source | Region | SubRegion | Country/Territory | DrugGroup | Drug | LevelOfSale | Year | Typical purity | Minimum purity | Maximum purity | Purity | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 289 | DAINAP | Asia | East and South-East Asia | Viet Nam | NPS | Ketamine and phencyclidine-type substances | Street | 2019 | 10000.0 | 18.0 | 85.0 | % (percent) |
| 526 | ARQ | Europe | Western and Central Europe | Belgium | Cocaine-type | Cocaine | Street | 2018 | 66.0 | 1.0 | 10000.0 | % (percent) |
| 527 | ARQ | Europe | Western and Central Europe | Belgium | Cocaine-type | Cocaine | Street | 2017 | 66.0 | 4.0 | 10000.0 | % (percent) |
| 866 | ARQ | Europe | Western and Central Europe | Luxembourg | “Ecstasy”-type substances | “Ecstasy”-type substances | Street | 2016 | 4229.0 | 121.0 | 9557.0 | % (percent) |
| 1198 | ARQ | Europe | South-Eastern Europe | Bulgaria | Cannabis-type drugs | Cannabis resin (hashish) | Retail | 2020 | 66.0 | 60.0 | 3950.0 | % (percent) |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1555 | ARQ | Europe | South-Eastern Europe | Turkey | Cannabis-type drugs | Cannabis herb (marijuana) | Wholesale | 2020 | 297.0 | 8.0 | 2109.0 | % (percent) |
| 1556 | ARQ | Europe | South-Eastern Europe | Turkey | Cannabis-type drugs | Cannabis resin (hashish) | Wholesale | 2020 | 609.0 | 24.0 | 2895.0 | % (percent) |
| 1557 | ARQ | Europe | South-Eastern Europe | Turkey | Cocaine-type | Cocaine-type drugs | Retail | 2020 | 5061.0 | 31.0 | 9549.0 | % (percent) |
| 1558 | ARQ | Europe | South-Eastern Europe | Turkey | Opioids | Heroin | Retail | 2020 | 2001.0 | 124.0 | 8600.0 | % (percent) |
| 1559 | ARQ | Europe | South-Eastern Europe | Turkey | Amphetamine-type stimulants | Methamphetamine powder | Retail | 2020 | 7355.0 | 121.0 | 10000.0 | % (percent) |
330 rows × 12 columns
Acima vemos a confirmação dos dados discrepantes, no caso temos porcentagens maiores do que 100%, talvez por um erro de digitação na hora de realizar o registro. Substituirei pela mediana:
mediana_typical = purities['Typical purity'].median()
mediana_minimum = purities['Minimum purity'].median()
mediana_maximum = purities['Maximum purity'].median()
purities.loc[(purities['Typical purity'] > 100), 'Typical purity'] = mediana_typical
purities.loc[(purities['Minimum purity'] > 100), 'Minimum purity'] = mediana_minimum
purities.loc[(purities['Maximum purity'] > 100), 'Maximum purity'] = mediana_maximum
purities.loc[(purities['Typical purity'] > 100) | (purities['Minimum purity'] > 100) | (purities['Maximum purity'] > 100)]| Source | Region | SubRegion | Country/Territory | DrugGroup | Drug | LevelOfSale | Year | Typical purity | Minimum purity | Maximum purity | Purity |
|---|
Agora acima vemos que não temos mais dados acima de 100% de pureza. Somente a titulo de curiosidade, a mediana da pureza era de 66%.
Por ultimo verificarei se existem dados duplicados:
purities.duplicated().sum()0Como não temos nenhum dado duplicado, seguiremos com nosso projeto.
Análise Exploratória de Dados
Bom, os cientistas mais observadores já perceberam que tenho 3 Features de Pureza, sendo elas: Typical, Minimum e Maximum. Nesse EDA irei trabalhar apenas com a Typical, pois é a pureza Típica, logo faz mais sentido trabalhar apenas com ela.
purities.head()| Source | Region | SubRegion | Country/Territory | DrugGroup | Drug | LevelOfSale | Year | Typical purity | Minimum purity | Maximum purity | Purity | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ARQ | Africa | East Africa | Kenya | Cocaine-type | Cocaine | Wholesale | 2019 | 15.0 | 25.0 | 30.0 | % (percent) |
| 1 | ARQ | Africa | East Africa | Kenya | Cocaine-type | Cocaine | Street | 2019 | 10.0 | 5.0 | 15.0 | % (percent) |
| 2 | ARQ | Africa | East Africa | Kenya | Opioids | Heroin | Street | 2019 | 10.0 | 5.0 | 15.0 | % (percent) |
| 3 | ARQ | Africa | East Africa | Kenya | Opioids | Heroin | Wholesale | 2019 | 25.0 | 30.0 | 60.0 | % (percent) |
| 4 | ARQ | Africa | North Africa | Algeria | Cannabis-type drugs | Cannabis resin (hashish) | Street | 2018 | 13.0 | 5.0 | 20.0 | % (percent) |
Abaixo vemos a distribuição de nossa Target (Feature que usaremos de forma predominante)
sns.distplot(purities['Typical purity'], color='skyblue')UserWarning:
`distplot` is a deprecated function and will be removed in seaborn v0.14.0.
Please adapt your code to use either `displot` (a figure-level function with
similar flexibility) or `histplot` (an axes-level function for histograms).
For a guide to updating your code to use the new functions, please see
https://gist.github.com/mwaskom/de44147ed2974457ad6372750bbe5751
sns.distplot(purities['Typical purity'], color='skyblue')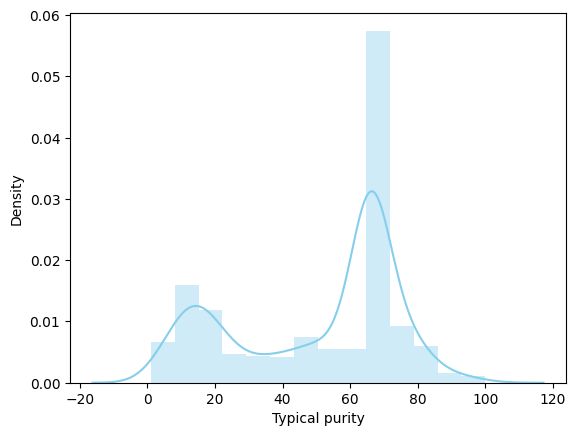
Qual continente obteve o maior índice de pureza de droga? (Anual)
Gráfico 1
No primeiro gráfico temos a qualidade de cada região no ano de 2016, podemos ver claramente que as Americas obtinham as drogas com melhor qualidade, tendo uma pureza de quase 64%. Quando digo Americas isso inclui os paises: ‘Costa Rica’, ‘El Salvador’, ‘Guatemala’, ‘Panama’, ‘Mexico’, ‘United States of America’, ‘Paraguay’, ‘Chile’, ‘Peru’. O segundo continente com a melhor qualidade de drogas era a Ásia seguida da África.
Gráfico 2
No ano de 2017 podemos perceber uma queda geral na qualidade de drogas pelo mundo, a Ásia que no ano anterior era a 2ª colocada, no ano de 2017 se torna a região com a droga de melhor qualidade, tendo uma pureza de 54.31%, seguida de Oceania e Americas. Nesse contexto Ásia é composta pelos seguintes paises: ‘Georgia’, ‘Kazakhstan’, ‘Kyrgyzstan’, ‘Tajikistan’, ‘Brunei Darussalam’, ‘Cambodia’, ‘China’, ‘Indonesia’, ‘Malaysia’, ‘Mongolia’, ‘Philippines’, ‘Thailand’, ‘Viet Nam’, ‘Lebanon’, ‘India’, ‘Sri Lanka’, ‘China, Macao SAR’, ‘China, Hong Kong SAR’.
Gráfico 3
Já no ano de 2018 vemos um aumento consideravel na qualidade das drogas, porém em contraponto vemos uma brusca queda da qualidade das drogas na África, muito provavelmente devido as crises humanitárias, ataques e epidemias que diversos paises Africanos sofreram no ano observado. A região que teve a melhor qualidade de drogas foi a Oceania com 61.25% de pureza, nesse contexto a Oceania é composta por apenas 2 paises, sendo eles: ‘Australia’ e ‘New Zealand’.
Gráfico 4
No quarto e ultimo gráfico temos o ano de 2019, neste ano a Oceania continua liderando o ranking de maior pureza em drogas com agora 73% de pureza.
Abaixo podemos ver qual região (continente) obteve uma maior qualidade de drogas. Note que não temos o ano de 2020, decidi retira-lo pois muito provavelmente por conta da pandemia a coleta de dados foi pausada, logo não tenho dados o suficiente para retirar insights significativos.
anos = [2016, 2017, 2018, 2019]
num_colunas = len(anos)
fig, axs = plt.subplots(1, num_colunas, figsize=(7*num_colunas, 5))
for i, ano in enumerate(anos):
purities_ano = purities[purities['Year'] == ano]
average_purity_by_region = purities_ano.groupby('Region')['Typical purity'].mean().reset_index()
region_with_highest_purity = average_purity_by_region.loc[average_purity_by_region['Typical purity'].idxmax()]
axs[i].bar(average_purity_by_region['Region'], average_purity_by_region['Typical purity'], color='skyblue')
axs[i].set_xlabel('Região')
axs[i].set_ylabel('Pureza Média')
axs[i].set_title(f'Pureza Média em {ano}')
axs[i].tick_params(axis='x', rotation=45)
axs[i].annotate(f'Maior Pureza: {region_with_highest_purity["Region"]} ({region_with_highest_purity["Typical purity"]:.2f}%)',
xy=(region_with_highest_purity['Region'], region_with_highest_purity['Typical purity']),
xytext=(10, 7), textcoords='offset points',
arrowprops=dict(arrowstyle='->', color='red', lw=1.5))
plt.tight_layout()
plt.show()
Qual continente obteve o maior índice de pureza de drogas? (Todos os anos)
No gráfico abaixo podemos ver que a região com a droga mais pura foi a Ásia, aqui considerei todos os anos.
E para isso tive que calcular a pureza média por região para cada ano, depois tive que fazer a média ao longo de todos os anos, e só depois disso que podemos encontrar a região com a maior média de pureza de todos os anos.
A qualidade das drogas pode ser influenciada por diferentes aspectos, sendo alguns deles:
Métodos de Produção: Diferentes regiões podem ter diferentes métodos de produção e fabricação de drogas ilícitas. A qualidade do produto final pode variar dependendo dos produtos químicos utilizados e das habilidades dos fabricantes.
Fonte de Matéria-Prima: A qualidade das matérias-primas utilizadas na produção de drogas ilícitas pode variar, afetando a pureza e a potência do produto final.
Controle de Qualidade: A falta de regulamentação e controle de qualidade em mercados ilegais pode resultar em produtos de qualidade inferior. Por outro lado, em algumas regiões, grupos criminosos podem ter padrões de qualidade rigorosos para manter sua reputação e aumentar os lucros.
Legislação e Policiamento: A eficácia das leis de combate às drogas e as atividades de policiamento podem influenciar a qualidade e a disponibilidade de drogas ilícitas em uma região específica. O rigor das políticas de repressão ao tráfico de drogas também pode afetar a disponibilidade e a qualidade das substâncias.
average_purity_by_region = purities.groupby(['Year', 'Region'])['Typical purity'].mean().reset_index()
average_purity_overall = average_purity_by_region.groupby('Region')['Typical purity'].mean().reset_index()
region_with_highest_average_purity = average_purity_overall.loc[average_purity_overall['Typical purity'].idxmax()]
plt.figure(figsize=(10, 6))
plt.bar(average_purity_overall['Region'], average_purity_overall['Typical purity'], color='skyblue')
plt.xlabel('Região')
plt.ylabel('Média de Pureza (%)')
plt.title('Média de Pureza por Região (Todos os Anos)')
plt.annotate(f'Região com Maior Média: {region_with_highest_average_purity["Region"]} ({region_with_highest_average_purity["Typical purity"]:.2f}%)',
xy=(region_with_highest_average_purity['Region'], region_with_highest_average_purity['Typical purity']),
xytext=(10, 10), textcoords='offset points',
arrowprops=dict(arrowstyle='->', color='red', lw=1.5))
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()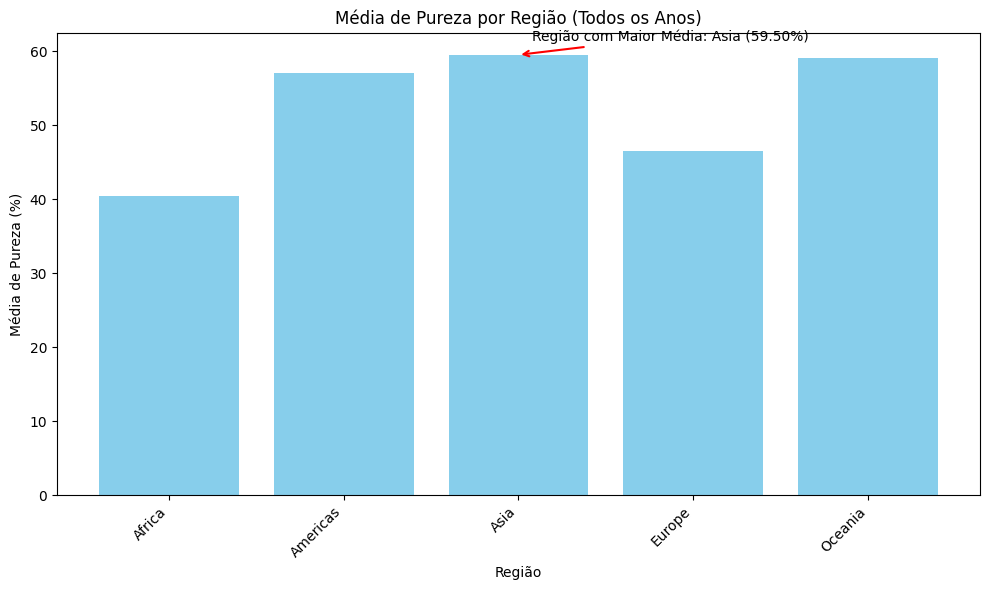
Das Américas, qual país tem o maior índice de pureza? (Todos os anos)
A seguir irei mostrar o país de cada região que obtém a droga mais pura de acordo com uma média feita de todos os anos.
Podemos fazer um ranking dos Países com maior pureza e seus respectivos continentes/regiões:
- 1º Lugar: Costa Rica - Americas (83.33%);
- 2º Lugar: Nova Zelândia - Oceania (73%)
- 3º Lugar: Ghana - África (72.17%)
- 4º Lugar: Líbano - Asia (71.66%)
- 5º Lugar: Croácia - Europa (66%%)
class TextColor:
WARNING = '\033[93m'
ENDC = '\033[0m'
regions = ['Americas', 'Asia', 'Oceania', 'Africa', 'Europe']
for region in regions:
region_data = purities[purities['Region'] == region]
best_country = region_data.groupby('Country/Territory')['Typical purity'].mean().idxmax()
best_quality = region_data.groupby('Country/Territory')['Typical purity'].mean().max()
print(f"Na região {TextColor.WARNING}{region}{TextColor.ENDC}, o país com a melhor qualidade média é {TextColor.WARNING}{best_country}{TextColor.ENDC} com uma qualidade média de {TextColor.WARNING}{best_quality:.2f}%{TextColor.ENDC}.")Na região Americas, o país com a melhor qualidade média é Costa Rica com uma qualidade média de 83.33%.
Na região Asia, o país com a melhor qualidade média é Lebanon com uma qualidade média de 71.60%.
Na região Oceania, o país com a melhor qualidade média é New Zealand com uma qualidade média de 73.00%.
Na região Africa, o país com a melhor qualidade média é Ghana com uma qualidade média de 72.17%.
Na região Europe, o país com a melhor qualidade média é Croatia com uma qualidade média de 66.00%.Drogas que são mais puras no mundo (Todos os anos)
Podemos ver que o grupo de drogas que é mais “bem feita”, ou seja, tem uma qualidade e pureza maior é o grupo do “Ecstasy”-Tipo Substância com 67.78% de pureza, seguida da Cocaína e do NPS. Isso se dá basicamente pelo fato de que as outras drogas são facilmente misturadas com outras substâncias enquanto o Ecstasy geramente é feito em locais controlados. Além disso, em uma breve pesquisa podemos levar em consideração os pontos abaixo:
Síntese Controlada: O Ecstasy é uma droga sintética que pode ser produzida em laboratórios controlados. Isso permite um maior grau de controle sobre o processo de produção e a qualidade dos ingredientes usados. Ao contrário das drogas produzidas em ambientes clandestinos, onde a qualidade e a pureza podem variar significativamente, os laboratórios de fabricação de Ecstasy podem seguir procedimentos mais rigorosos.
Demanda por Qualidade: Os consumidores de Ecstasy muitas vezes valorizam a qualidade e a pureza da substância, pois isso afeta diretamente os efeitos desejados e reduz os riscos para a saúde. Produtores e traficantes que desejam manter uma “clientela leal” podem optar por fornecer produtos de maior qualidade para atender a essa demanda.
average_purity_by_group = purities.groupby(['Year', 'DrugGroup'])['Typical purity'].mean().reset_index()
average_purity_overall = average_purity_by_group.groupby('DrugGroup')['Typical purity'].mean().reset_index()
group_with_highest_average_purity = average_purity_overall.loc[average_purity_overall['Typical purity'].idxmax()]
plt.figure(figsize=(10, 6))
plt.bar(average_purity_overall['DrugGroup'], average_purity_overall['Typical purity'], color='skyblue')
plt.xlabel('Grupo da Droga')
plt.ylabel('Média de Pureza (%)')
plt.title('Média de Pureza por Droga (Todos os Anos)')
plt.annotate(f'Grupo de droga com maior pureza: {group_with_highest_average_purity["DrugGroup"]} ({group_with_highest_average_purity["Typical purity"]:.2f}%)',
xy=(group_with_highest_average_purity['DrugGroup'], group_with_highest_average_purity['Typical purity']),
xytext=(10, 10), textcoords='offset points',
arrowprops=dict(arrowstyle='->', color='red', lw=1.5))
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()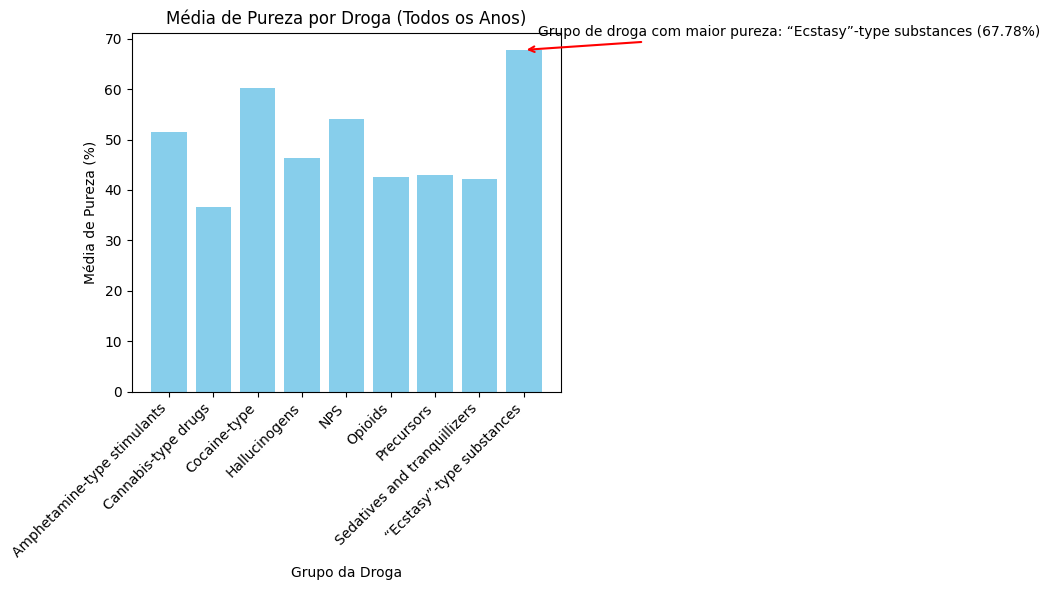
Qual nível de venda obtém uma maior pureza?
Tenho 3 níveis de venda em meu dataset, sendo eles:
- Retail - Varejo
- Street - Rua
- Wholesale - Atacado
No gráfico abaixo podemos retirar alguns insights significantes. Vemos que o nível de venda que obtém a maior pureza ou qualidade, é o Varejo, ou seja, drogas vendidas em Varejos tem uma qualidade maior comparadas as que são vendidas em Atacado, que por sua vez, tem uma qualidade maior do que aquelas que são vendidas em Rua. Isso se da por diversos fatores, mas não significa que sempre as drogas vendidas em Varejo tem uma qualidade maior.
Fazendo novamente uma pequena e rápida pesquisa para embasar meus argumentos, chego a algumas conclusões do porque drogas vendidas em nivel de Varejo tem uma qualidade maior:
Cadeia de Fornecimento Controlada: Em algumas situações, as drogas vendidas no varejo podem passar por uma cadeia de fornecimento mais controlada, o que pode ajudar a garantir uma qualidade mais consistente. Isso pode ser o caso em locais onde a produção e distribuição de drogas são mais regulamentadas.
Falsificações Menos Comuns: Em mercados de varejo, as falsificações podem ser menos comuns, pois os consumidores podem ter mais confiança de que estão obtendo o que compraram. Isso pode levar à percepção de uma qualidade melhor.
Seleção do Consumidor: Os consumidores de drogas em varejo podem ter a oportunidade de escolher entre diferentes produtos e fornecedores. Isso pode levar à compra de produtos de fornecedores conhecidos por qualidade consistente.
Menos Diluição: Em alguns casos, as drogas vendidas em varejo podem estar menos diluídas com substâncias inativas do que as drogas vendidas em grande quantidade no atacado. Isso pode levar a uma percepção de maior potência.
Podemos fazer uma rápida ligação disso tudo com a série ‘Breaking Bad’ (que pessoalmente gosto muito), quem assistiu o seriado sabe que inicialmente o personagem principal produzia Metanfetamína a nivel de Varejo, e desde o incio até o final da série vemos a sua preocupação com a qualidade do produto e até mesmo higiene do local de trabalho (afinal, antes de tráficante ele é um químico). Isso nos faz pensar em uma relação direta entre quanto maior o nivel de venda, maior a qualidade e maior o preço.
average_purity_by_level = purities.groupby(['Year', 'LevelOfSale'])['Typical purity'].mean().reset_index()
average_purity_overall = average_purity_by_level.groupby('LevelOfSale')['Typical purity'].mean().reset_index()
level_with_highest_average_purity = average_purity_overall.loc[average_purity_overall['Typical purity'].idxmax()]
plt.figure(figsize=(10, 6))
plt.bar(average_purity_overall['LevelOfSale'], average_purity_overall['Typical purity'], color='skyblue')
plt.xlabel('Nivel de venda')
plt.ylabel('Média de Pureza (%)')
plt.title('Média de pureza por niveis de venda (Todos os Anos)')
plt.annotate(f'Nivel de venda com maior pureza: {level_with_highest_average_purity["LevelOfSale"]} ({level_with_highest_average_purity["Typical purity"]:.2f}%)',
xy=(level_with_highest_average_purity['LevelOfSale'], level_with_highest_average_purity['Typical purity']),
xytext=(10, 5), textcoords='offset points',
arrowprops=dict(arrowstyle='->', color='red', lw=1.5))
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()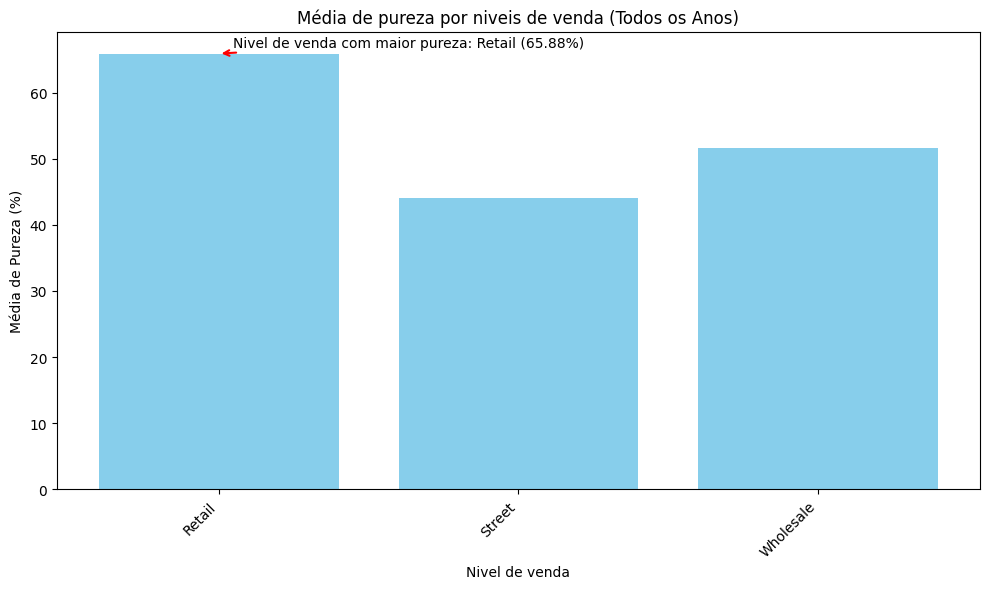
Conclusão
Depois de decompor esse dataset, fazer relações, hipóteses, etc. Tenho algumas considerações finais dessa Analise Exploratória. Vimos que o continente com a droga de maior qualidade é a Ásia por motivos diversos, porém o país que obtém a “melhor” droga é a Costa Rica nas Americas. Vimos também que a droga mais “pura” no mundo é o Ecstasy, também por motivos diversos e ao final, as drogas vendidas em varejo tem uma qualidade maior e consequentemente um preço maior.
Lembrando que é importante não romantizar ou glorificar atividades ilegais relacionadas a droga e vale ressaltar que o consumo de drogas ilícitas é ilegal em muitos lugares e pode ser perigoso para a saúde física e mental. Buscar ajuda e apoio de profissionais de saúde é fundamental para aqueles que enfrentam problemas relacionados a drogas. A qualidade e a pureza das substâncias não devem ser usadas como justificativa para o uso de drogas ilícitas. Este é apenas um trabalho de demonstração de habilidades de Ciência de Dados e não um trabalho que busque justificativas ou argumentos para o uso de drogas.
Obrigado por me acompanhar nesta viagem!
Que tal começarmos outra?
🚀