#Limpeza, visualização, processamento de dados
import pandas as pd
import statistics as sts
import numpy as np
import seaborn as srn
import matplotlib.pyplot as plt
#Divisão de dados e Feature Selection
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
#Modelos
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
#Encoder e métricas
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import classification_report, confusion_matrixDesenvolvendo um Modelo de Classificação de Crédito usando Machine Learning.
Autor: SergioJr
Data: 09 de Outubro de 2023
Categorias: Ciência de Dados, Machine Learning, Projeto Prático

No cenário financeiro atual, a decisão de emprestar dinheiro a um indivíduo é uma tarefa crítica para as instituições financeiras. Garantir que o empréstimo seja concedido a pessoas elegíveis é fundamental para minimizar riscos e manter a estabilidade financeira.
O objetivo deste projeto, além de fazer uma analise da base de dados, é desenvolver um modelo de classificação de crédito usando técnicas de Machine Learning para determinar se um indivíduo é apto ou não a receber um empréstimo, o mesmo que grandes empresas usam para determinar se você é apto ou não a receber empréstimo, de acordo com os dados que elas tem. Compreender como os modelos de classificação de crédito funcionam não apenas aprimora a eficiência das instituições financeiras, mas também pode ajudar a tornar o processo de concessão de empréstimos mais justo e transparente para os consumidores.
Se você ainda não viu minha série de 3 artigos explicando de forma lúdica como funciona o Machine Learning, clique aqui para ler o primeiro artigo e entender mais sobre esse mundo maravilhoso!
Neste artigo, abordarei cada etapa do processo, desde a coleta e limpeza de dados até a construção e avaliação do modelo. Você terá uma visão abrangente de como a ciência de dados pode ser aplicada para tomar decisões informadas no setor financeiro.
Coleta e Primeira visão dos dados
Os dados são da Alura Challenges, não cheguei a realizar o desafio na época que ele foi disponibilizado, não segui o roteiro deles e fiz o meu próprio “desafio”.
Em todos os meus projetos eu gosto de fazer o que chamo de “Data First View”, onde é literalmente uma pequena analise onde vejo os dados pela primeira vez e defino o que será feito na limpeza e no tratamento dos dados. Também costumo fazer um pequeno dicionário de dados, nesse caso eu já tinha um dicionário disponível.
Antes de tudo, tenho que fazer as importações das bibliotecas que necessito:
Vamos agora ver como são os dados, o Pandas nos ajudará com isso, veremos apenas os 5 primeiros registros da minha base de dados:

Com um simples df.shape vejo que tenho 34mil dados distribuídos em 12 colunas (ou Features). Verifico também os tipos de dados que estou trabalhando, então um df.dtypes me revela que em sua maioria os dados estão no formato float64, porém entre eles temos dados do formato object (strings).
Agora que já sabemos com quantos dados iremos trabalhar e com qual tipo de dado estamos trabalhando, veremos se existem dados ausentes:
for col in df.columns:
porcentagem = round(df[col].isna().mean() * 100, 2)
print(f'{col}: {porcentagem}%')person_age float64
person_income float64
person_home_ownership object
person_emp_length float64
loan_intent object
loan_grade object
loan_amnt float64
loan_int_rate float64
loan_status float64
loan_percent_income float64
cb_person_default_on_file object
cb_person_cred_hist_length float64
dtype: objectAcima vemos a porcentagem de valores ausentes em cada coluna e quais colunas possuem dados ausentes.
Lidando com dados ausentes.
Lidar com dados ausentes a primeira vista parece uma tarefa difícil, pois os dados ali simplesmente não existem, então, o que fazer? Nesse caso tenho 2 opções, eu posso deletar os dados ou eu posso substitui-los pela mediana dos valores da coluna onde o dado ausente se encontra. Nesse projeto escolho a segunda opção, porém eu poderia ter escolhido a primeira.
Por que usar a mediana e não a média? A mediana é a melhor escolha por ser mais confiável pois ela não é influenciada por valores extremos ou mínimos (outliers):
for col in ["person_age", "person_income", "person_emp_length", "loan_amnt", "loan_int_rate", "loan_status", "loan_percent_income", "cb_person_cred_hist_length"]:
df[col].fillna(df[col].median(), inplace=True)Um simples laço de repetição for é o suficiente para substituirmos os valores ausentes de cada coluna numérica com a mediana da mesma. Porém não é só de dados numéricos que se faz um dataset concorda? E no meu eu tenho colunas categóricas que também tem dados ausentes, e nesse caso irei substitui-los pela palavra reservada “Unknown”, isso ajudará em nosso EDA e posteriormente em nossa modelagem de dados:
df.person_home_ownership.fillna('Unknown', inplace=True)
df.loan_intent.fillna('Unknown', inplace=True)
df.loan_grade.fillna('Unknown', inplace=True)
df.cb_person_default_on_file.fillna('Unknown', inplace=True)Por fim, exterminamos todos os dados faltantes desse dataframe!
Verificando e lidando com erros nos dados
Meu objetivo aqui é verificar se existem dados com valores discrepantes, valores negativos e outros erros que podem eventualmente atrapalhar meu EDA e minha modelagem.
Primeiro veremos se existem valores negativos em minhas colunas numéricas:
for col in ["person_age", "person_income", "person_emp_length", "loan_amnt", "loan_int_rate", "loan_status", "loan_percent_income", "cb_person_cred_hist_length"]:
if df[col].min() < 0:
print(f"Existem valores negativos na coluna: {col}")
else:
print(f"Não existem valores negativos na coluna: {col}")Não existem valores negativos na coluna: person_age
Não existem valores negativos na coluna: person_income
Não existem valores negativos na coluna: person_emp_length
Não existem valores negativos na coluna: loan_amnt
Não existem valores negativos na coluna: loan_int_rate
Não existem valores negativos na coluna: loan_status
Não existem valores negativos na coluna: loan_percent_income
Não existem valores negativos na coluna: cb_person_cred_hist_lengthVejo que não tenho o problema de dados negativos, porém além dessa verificação primária é importante fazer uma descrição estatística de nossas colunas para termos certeza que não temos dados negativos.
Depois disso, temos que verificar se não temos dados discrepantes (outliers), para isso utilizarei uma técnica chamada de Máscara Booleana (ou Query para os mais íntimos) para filtrarmos apenas os dados que queremos, no caso os dados de pessoas que foram registradas erroneamente com idades acima de 110 anos, farei esse mesmo processo de máscara booleana para todos os outros filtros. Substituirei os outliers pela mediana (neste caso a mediana era 26 anos):
mediana = df.person_age.median() #obtenção da mediana da coluna de idade
#Se em minha coluna existir valores maiores que 110, substitua por mediana
df.loc[( df['person_age'] > 110), 'person_age'] = mediana
df.loc[( df['person_age'] > 110), 'person_age']Farei o mesmo processo para a coluna ‘person_emp_lenght’. Pesquisei qual a media de anos trabalhados e cheguei em um numero de 40 anos. É esse que usaremos para nossa Máscara Booleana e para substituir nossos dados. O processo é o mesmo descrito acima.
Por último, verificarei se não existem dados duplicados, o que também é um empecilho pois pode causar enviesamento de meu modelo e de minha EDA. E para resolver esse pequeno problema, eu irei deletar os dados duplicados:
df.duplicated().sum() #Contagem de dados duplicados (165)
#Deletar dados duplicados
df.drop_duplicates(keep='first',inplace=True)E com isso temos os nossos dados limpos e sem erros!
EDA: Dados de Clientes
Nossos dados são “divididos” em dados de clientes e dados e empréstimo, farei primeiro a Analise Exploratória nos dados de clientes e posteriormente no de empréstimos.
Vejamos a distribuição dos anos trabalhados dos clientes:
srn.histplot(df['person_emp_length'])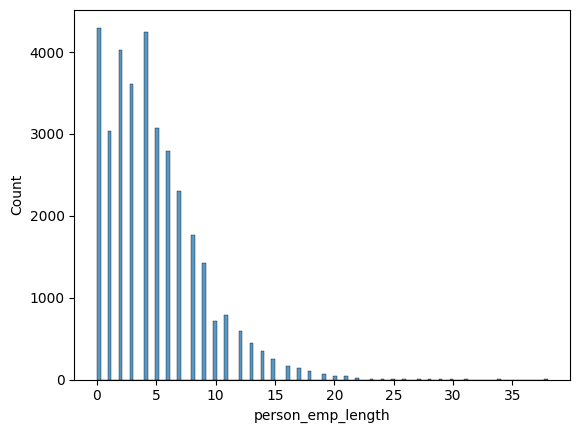
Com base no gráfico acima é possível ver que quem pede empréstimo geralmente ou não tem nem 1 ano trabalhados ou estão entre 5 a 6 anos de trabalho.
Vejamos agora a situação de moradia dos clientes:
srn.histplot(df['person_home_ownership'])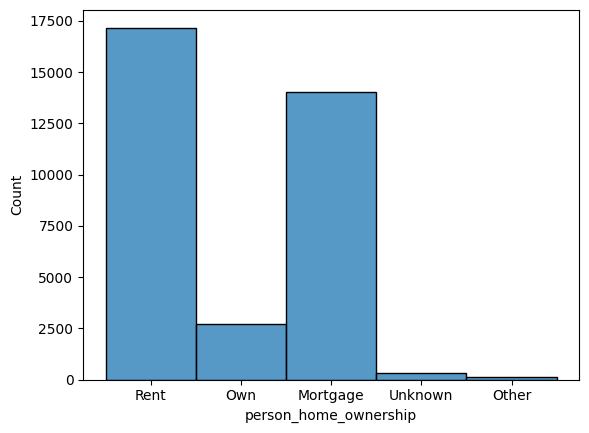
Pode-se notar que em sua maioria nossos clientes pagam aluguel, ou seja, um gasto a mais.
Vamos aos dados de idade de nossos clientes:
srn.histplot(df['person_age'])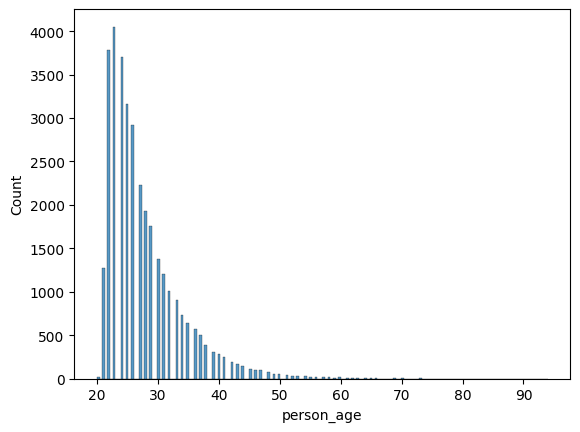
Aqui podemos ver que geralmente quem mais pede empréstimo tem uma idade de entre 20 a 30 anos.
Para fechar nossa EDA dos clientes, vamos ver o valor total de empréstimo por idade:
srn.barplot(data=df, x="person_age", y="loan_amnt")
plt.title("Valor total do empréstimo por idade")
plt.xlabel("Idade")
plt.ylabel("Valor total do empréstimo")
plt.subplots_adjust(left=-2, bottom=0.3)
plt.show()
No gráfico anterior vimos que a idade de quem mais pede empréstimo está entre 20 a 30 anos porém neste outro gráfico podemos ver que apesar de quem pedir mais empréstimo são as pessoas mais novas quem pede empréstimos de maior valor são os idosos, talvez isso se dê pela situação financeira já estável ou pela necessidade, assim como vimos que a maioria dos objetivos dos empréstimos são saúde e educação.
logo temos a seguinte hipótese: Pessoas mais novas pedem mais empréstimo para educação e pessoas mais idosas pedem menos empréstimo, porém quando pedem, pedem um valor maior, talvez para saúde. Validarei ela logo abaixo.
EDA: Dados de Empréstimo
Aqui validarei a hipótese que criei acima, observe atentamente o gráfico abaixo:
srn.histplot(df['loan_intent'])
plt.subplots_adjust(left=-0.4, bottom=0.3)
plt.show()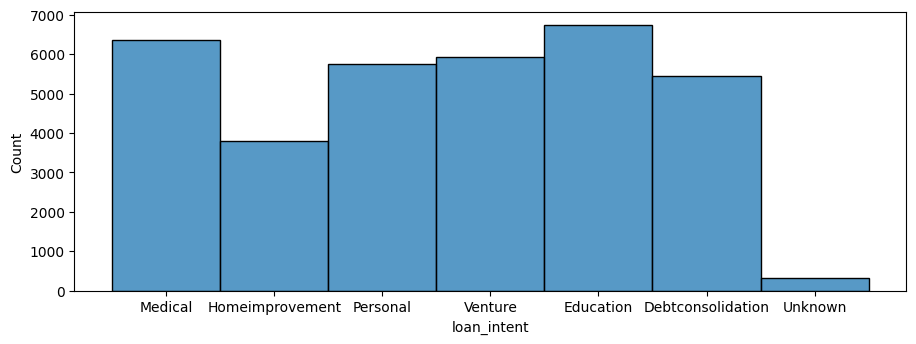
Acima vemos a contagem de intenção de empréstimo, ou seja, com qual intenção o empréstimo foi pedido. Vemos que em sua maioria pessoas pedem empréstimo para principalmente educação e saúde. Isso por si só nos leva a hipótese criada na EDA dos Clientes. Não contente com apenas isso, vamos ver a contagem dos principais valores pedidos em empréstimo:
srn.histplot(df['loan_amnt'])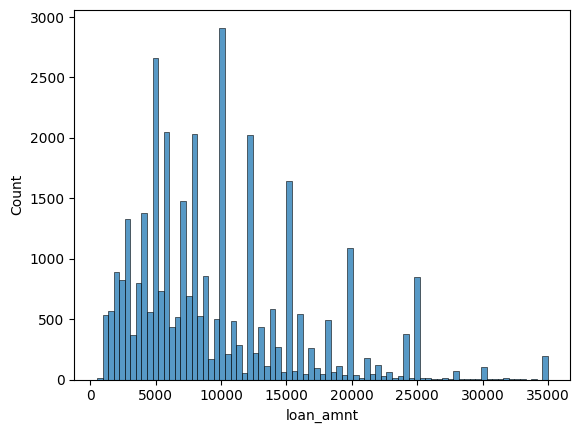
A maioria pede entre 5 a 10 mil, alguma grande maioria pede 15mil, a minoria pede valores acima de 30 mil.
Divisão dos dados
Aqui farei a divisão dos dados e a técnica de LabelEncoding para a transformação de features categóricas em numéricas para então passa-las para meu modelo.
A técnica de LabelEncoding foi escolhida no lugar do OneHotEncoding pois temos Features que são categóricas ordinais (loan_grade) ou seja, elas tem uma ordem especifica que deve ser seguida.
Divido meu dataframe em 2, em X tenho os dados previsores, os que serão usados para prever y. Em X tenho todos os dados menos meu Target. Em y tenho meu Target em si, que é a coluna “loan_status” (situação do empréstimo).
X = df.drop(['loan_status'], axis=1) # Variáveis de previsores (features)
y = df['loan_status'] # Variável de classe (rótulos)
X.head()Após isso tenho que realizar o LabelEncoding no meu X e apenas nas colunas categóricas:
labelencoder1 = LabelEncoder()
X['person_home_ownership'] = labelencoder1.fit_transform(X['person_home_ownership'])
labelencoder2 = LabelEncoder()
X['loan_intent'] = labelencoder2.fit_transform(X['loan_intent'])
labelencoder3 = LabelEncoder()
X['loan_grade'] = labelencoder3.fit_transform(X['loan_grade'])
labelencoder4 = LabelEncoder()
X['cb_person_default_on_file'] = labelencoder4.fit_transform(X['cb_person_default_on_file'])
Com isso eu tenho todos os dados em formato numérico. Porém com isso tenho outro problema, os tipos de dados diferentes. Podemos ver na imagem acima que em meu dataset tenho dados do tipo float e do tipo int. Então transformarei todos em int (inteiro):
X = X.astype(int)
y = y.astype(int)Agora com nossas colunas de nosso dataset previsor todas em formato numérico e em formatos de dados iguais, iremos realizar o train_test_split (a divisão de nossos dados em dados de teste e treino):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0)Mais ou menos 30% do meu dataset será usado para o teste do modelo, os outros 70% serão usados para treinamento.
Feature Selection
Utilizaremos técnicas de testes estatísticos univariados (SelectKBest) para fazermos a seleção dos recursos que serão usados em meu modelo (tanto para teste quanto para treino).
Neste projeto foi usado o SelectKBest (skb) por sua eficiência e simplicidade, porém poderiamos ter utilizado outras técnicas como FeatureImportance, RFE, etc.
O SelectKBest irá escolher as 4 colunas que mais se correlacionam com nossa classe (k=4):
#Configurando o SelectKBest
skb = SelectKBest(score_func=chi2, k=4)baixo passo ao skb nossas features previsoras e nossa classe para ele fazer os testes estatísticos para descobrir a relevancia das features e suas relações:
skb.fit(X_train, y_train)X_train_skb = pd.DataFrame(skb.transform(X_train), columns = X_train.columns[skb.get_support()])
X_test_skb = pd.DataFrame(skb.transform(X_test), columns = X_test.columns[skb.get_support()])
X_train_skb.head()Isso nos retorna o seguinte dataframe:
person_income loan_grade loan_amnt loan_int_rate
0 52000 1 10000 12
1 69000 5 24000 15
2 105000 0 24000 10
3 94000 1 4800 10
4 70000 0 10000 7
Vemos acima que ele escollheu as 4 colunas mais relevantes para nosso modelo de acordo com nossa classe, sendo elas: ‘person_income’, ‘loan_grade’, ‘loan_amount’ e ‘loan_int_rate’. Porém, faz sentido? Vejamos:
person_income: É razoável supor que a renda da pessoa pode influenciar significativamente a elegibilidade para empréstimos. Pessoas com renda mais alta podem ter maior probabilidade de receber empréstimos.
loan_grade: A classificação do empréstimo pode ser um indicador importante da qualidade do empréstimo. Em geral, empréstimos com classificações mais altas (melhor qualidade) podem ter maior probabilidade de serem elegíveis.
loan_amnt: O valor do empréstimo pode afetar a elegibilidade, pois empréstimos maiores podem ser mais difíceis de serem aprovados, dependendo da capacidade de pagamento do mutuário.
loan_int_rate: A taxa de juros pode ser um fator crítico na elegibilidade. Taxas de juros mais altas podem tornar os empréstimos menos acessíveis.
Então sim, podemos dizer que faz total sentido a escolha dessas features para treinarmos e avaliarmos nosso modelo. A partir de agora usarei essas colunas em meu X.
Dando vida ao Modelo
Como foi dito ao começo desse artigo, o objetivo do meu modelo é classificar um possível cliente em apto ou não a receber empréstimo baseado em seus dados históricos.
Fiz o teste com 4 modelos diferentes, sendo eles: ‘Naive Bayes’, ‘Logistic Regression’, ‘KNN’, ‘RandomForestClassifier’. Comparei suas métricas e o que teve uma métrica melhor (como verão mais a frente) foi o RandomForestClassifier, logo esse foi o escolhido.
model = RandomForestClassifier()
model.fit(X_train_skb, y_train)
predictions = model.predict(X_test_skb)Acima vemos o fit do modelo, o método Fit é usado para treinar o modelo com base nos dados de treinamento fornecidos, permitindo que o modelo aprenda os padrões nos dados e seja capaz de fazer previsões posteriormente.
Logo após utilizo o método predict() que é usado após o treinamento do modelo e é utilizado para fazer previsões com base nos dados de entrada. Quando você chama o método predict() em um modelo treinado, ele usa os parâmetros aprendidos durante o treinamento para realizar previsões em novos dados ou em dados de teste.
Avaliando meu modelo
A avaliação do modelo é uma etapa importante do projeto pois isso nos mostrará qual o modelo ideal para nossos dados e para sabermos se nosso trabalho encima dos dados até aqui foi bem feito ou não. Vejamos a matriz de confusão e o classification report do modelo que foi escolhido, o RandomForestClassifier:
print(confusion_matrix(y_test, predictions))[[8231 669]
[ 989 1442]]É um resultado razoável e aceitável. Vejamos o classification report do RandomForestClassifier:
print(classification_report(y_test, predictions)) precision recall f1-score support
0 0.89 0.92 0.91 8900
1 0.68 0.60 0.64 2431
accuracy 0.85 11331
macro avg 0.79 0.76 0.77 11331
weighted avg 0.85 0.85 0.85 11331Podemos ver resultados satisfatórios quando o modelo prevê que o cliente não é apto (0), porém para prever se é apto (1) ele tem um desempenho razoável.
Chegou a hora de compararmos os modelos. Abaixo montei um gráfico com todas as métricas de todos os modelos para fazermos uma rápida analise e comparativo para sabermos qual foi o melhor:
modelos = ['Naive Bayes', 'Logistic Regression', 'KNN', 'RandomForestClassifier']
acuracia = [0.80, 0.79, 0.81, 0.86]
precisao = [0.71, 0.74, 0.72, 0.79]
recall = [0.62, 0.55, 0.71, 0.76]
f1_score = [0.64, 0.54, 0.72, 0.78]
indice = np.arange(len(modelos))
largura = 0.2
plt.bar(indice, acuracia, largura, label='Acurácia', alpha=0.7)
plt.bar(indice + largura, precisao, largura, label='Precisão', alpha=0.7)
plt.bar(indice + 2 * largura, recall, largura, label='Recall', alpha=0.7)
plt.bar(indice + 3 * largura, f1_score, largura, label='F1-Score', alpha=0.7)
plt.xlabel('Modelos')
plt.ylabel('Métricas')
plt.title('Comparação de Métricas de Desempenho por Modelo')
plt.xticks(indice + largura * 1.5, modelos)
plt.legend()
plt.tight_layout()
plt.show() 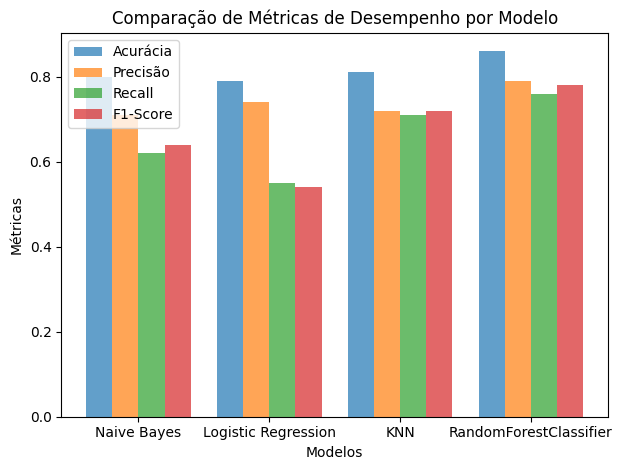
Do gráfico acima podemos retirar alguns insights, sendo eles:
O modelo RandomForestClassifier apresenta a maior acurácia (0.86), o que significa que é o mais preciso em termos de previsões corretas em relação ao total de previsões.
O modelo KNN tem uma boa acurácia (0.81) e um F1-Score sólido (0.72).
O modelo Naive Bayes tem a melhor precisão (0.71) e a melhor recall (0.62) entre os modelos.
O modelo Logistic Regression tem acurácia (0.79) e precisão (0.74) razoáveis.
Tendo isso em vista, o RandomForestClassifier parece ser o modelo que alcançou o melhor desempenho geral, com a maior acurácia, precisão, recall e F1-Score.
Conclusão
Ao longo deste projeto de análise de crédito, mergulhamos profundamente no universo da ciência de dados e desvendamos insights cruciais que podem influenciar a maneira como as instituições financeiras tomam decisões sobre empréstimos. Gostaria de resumir os principais resultados alcançados e discutir as implicações significativas que este projeto carrega consigo.
Desenvolvemos um modelo de classificação de crédito altamente preciso, que demonstrou um desempenho sólido na identificação de candidatos aptos e não aptos a receber empréstimos.
Durante a análise exploratória de dados (EDA), identificamos fatores-chave, que têm um impacto significativo nas decisões de concessão de empréstimos.
A seleção de recursos (Feature Selection) refinou nosso modelo, tornando-o mais eficiente e interpretável, com menos complexidade.
Com as métricas de desempenho em mãos, estamos confiantes de que nosso modelo pode ser uma ferramenta valiosa para instituições financeiras, permitindo-lhes tomar decisões mais precisas e informadas.
Muito obrigado por acompanhar esta jornada. Espero que este projeto tenha inspirado novas ideias e discussões em nosso campo em constante crescimento. Quaisquer dúvidas ou críticas construtivas serão bem vindas no campo dos comentários!
Obrigado por me acompanhar nesta viagem!
Que tal começarmos outra?
🚀